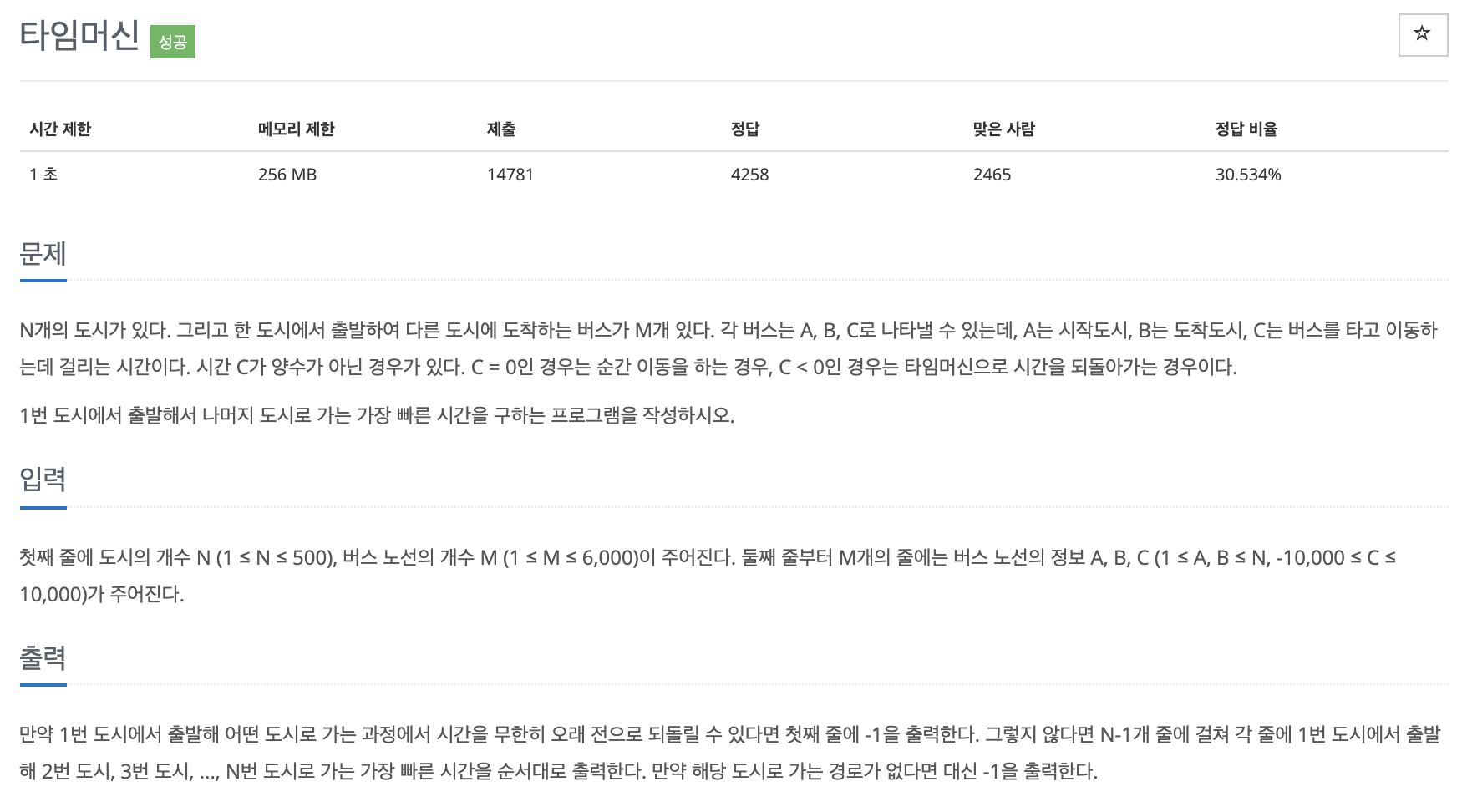
# 다익스트라 알고리즘은 어떠한 정점을 기준으로 잡고 다른 모든 정점으로의 최단 거리를 구하는 알고리즘이고, 플로이드 와샬은 모든 정점에서 모든 정점으로의 최단 거리를 구하는 알고리즘이다. 다익스트라는 가장 적은 비용을 가지는 간선을 하나씩 선택하여 알고리즘을 수행했다면, 플로이드 와샬은 거쳐가는 정점을 기준으로 알고리즘을 수행했다는 점이 특징이다.
다익스트라는 그리디 기법을 기반 / 플로이드 와샬은 다이나믹 프로그래밍 기반
플로이드-와샬 알고리즘(Floyd-Warshall Algorithm)은 그래프에서 모든 꼭짓점 사이의 최단 경로의 거리를 구하는 알고리즘이다. 음수 가중치를 갖는 간선도 순환만 없다면 잘 처리된다. 제일 바깥쪽 반복문은 거쳐가는 꼭짓점이고, 두 번째 반복문은 출발하는 꼭짓점, 세 번째 반복문은 도착하는 꼭짓점이다. 이 알고리즘은 플로이드 알고리즘이라고도 알려져 있다.
반복문 3개를 중첩하기 때문에, 시간 복잡도는 O(V^3)로 복잡하다.

public class floydwarshall {
static int INF = 999999;
public static void main(String[] args) {
int arr[][] = {{0, 1, INF, 4, 5},
{INF, 0, 3, 2, 1},
{1, INF, 0, 5, 3},
{INF, INF, 4, 0, 2},
{4, INF, 1, 7, 0}};
for(int i=0; i<arr.length; i++) {
for(int j=0; j<arr.length; j++) {
for(int k=0; k<arr.length; k++) {
if(arr[j][k] > arr[j][i] + arr[i][k])
arr[j][k] = arr[j][i] + arr[i][k];
}
}
}
for(int i=0; i<arr.length; i++) {
for(int j=0; j<arr.length; j++) {
System.out.print(arr[i][j]+ " ");
}System.out.println();
}
}
}
'알고리즘' 카테고리의 다른 글
| #알고리즘_벨만 포드(Bellman-Ford Algorithm) - Java (0) | 2020.01.11 |
|---|---|
| #알고리즘_조합과 순열(조합, 중복조합, 순열, 중복순열) - Java (0) | 2020.01.09 |
| #알고리즘_선형 탐색/이진 탐색 - Java (0) | 2020.01.08 |
| #알고리즘_신장 트리(Spanning Tree) (0) | 2020.01.08 |
| #알고리즘_프림(Prim Algorithm) - Java (0) | 2020.01.08 |